Additional Data Storage Topics – The Storage of Data

This section will help you increase your knowledge of two of Azure open‐source products and features, as well as provide a summary of the storage of data along the Big Data stages.
Storing Raw Data in Azure Databricks for Transformation
Data landing zones (DLZ) are categorized into Raw Files, cleansed data, and business data, and their equal terms of bronze, silver, and gold are synonymous. So far in this book, how data is stored on Azure Databricks behind the scenes might not be completely clear. There is an Azure storage account that contains numerous provisioned blob storage containers, along with your Azure Databricks service. The workspace uses the blob storage containers to store logs, jobs, meta, and the root container where your data is stored. Some restrictions are placed on the container to keep people from accessing the containers and any file or directory contained within them, most likely to keep curious people from accidentally changing something that may have negative or unintentional consequences for the workspace and the analytics performed on it. There is no way then to add files, for example, to that blob container and then access them from the Azure Databricks workspace. You can instead mount a different ADLS container to the Databricks File System (DBFS) and access your data stored on it. This capability aligns well with the DLZ stage alignment possibilities into multiple regions, as shown previously in Figure 4.13.
There are numerous ways to access data on your ADLS container. One method is to mount a DBFS path to it by using the following snippet:
dbutils.fs.mount(source = “wasbs://<container>@<account>.blob.core.windows.net”,mount_point = “/mnt<mountname>”,extra_configs={“fs.azure.account.key.<account>.blob.core.windows.net”:dbutils.secrets.get(scope = “<scope-name>”, key = “<key-name>”)})
The mounting procedure requires an Azure Key Vault (AKV) secret. AKV was introduced in Chapter 1 and will be covered in detail in Chapter 8.
The other way to access your data on ADLS is to use the following snippet, which stores the Azure Storage Access key in the Spark configuration file. This isn’t something you might feel comfortable doing, but it might be helpful during development activities. You can avoid doing this with AKV, which is the recommended approach.
spark.conf.set(“fs.azure.account.key.<account>.blob.core.windows.net”,
“4jRwk0Ho7LB+KHS9WevW7yuZP+AKrr1FbWbQ==”)
Note that the previous snippet should not have a line break, and the random characters are the Azure Storage account Access key.
The last approach discussed here is to add the following snippet to your Advanced options ➢ Spark configuration, like you did in Exercise 3.14. Doing this will apply the endpoint and credentials to the cluster at startup, making it available with no manual intervention.
fs.azure.account.key.<account>.blob.core.windows.net <access-key>
Then you can access the content as follows. Figure 4.40 shows the results.
df = spark.read. \
parquet(“wasbs://<container>@<account>.blob.core.windows.net/<directory-name>”)
print(df.count())
display(df.limit(10))
This flexibility means that you can directly access any ADLS container that contains raw files. Once the Raw Files are transformed, you can then store them in cleansed data or business data directories, containers, or storage accounts.
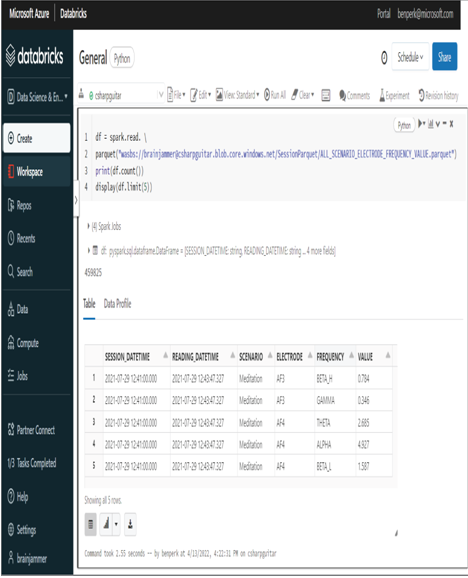
FIGURE 4.40 Storing raw data in Azure Databricks
Related Post

Implement a Serving Layer with a Star Schema – The Storage of Data-1
FIGURE 4.35 Serving layer using star schema distribution types FIGURE 4.36 Serving layer using star [...]
Implement Efficient File and Folder Structures – The Storage of Data
df = spark.read.load(‘abfss://@.dfs.core.windows.net/in-path/file.csv’, df.write.mode(“overwrite”) \ df = spark.read.load(‘abfss://@.dfs.core.windows.net/out-path/file.parquet’, print(df.count()) from pyspark.sql.functions import year, month, col [...]