Azure Synapse Analytics and ADLS – The Storage of Data

When you provision an Azure Synapse Analytics workspace, you choose a region to place it into. The associated ADLS storage container, although recommended to be in the same region, does not have to be, but in most cases it is. The point is, when there is an access problem in that region, what actions do you need to take? Refer to Figure 4.8 and notice, toward the bottom, a tile called Geo‐backup, which is enabled. If you click that, it routes to the Geo‐backup policy blade. When enabled, SQL pool backups are taken and stored in a paired datacenter with an RPO objective of 24 hours. Table 4.2 provides a few examples of paired datacenters (aka regions).
TABLE 4.2 Cross‐region replication pairings, paired datacenters
| Geography | Region A | Region B |
| Asia‐Pacific | East Asia (Hong Kong) | Southeast Asia (Singapore) |
| Australia | Australia East | Australia Southeast |
| Canada | Canada Central | Canada East |
| China | China North | China East |
| Europe | North Europe (Ireland) | West Europe (Netherlands) |
| India | Central India | South India |
| North America | East US | West US |
| South Africa | South Africa North | South Africa West |
| UK | UK West | UK South |
| United Arab Emirates | UAE North | UAE Central |
If you are placing your Azure Synapse Analytics workspace in West Europe and perform a backup, as you learned in Exercise 4.2, it is also stored in North Europe. The Geo‐backup policy blade enables you to disable this feature. Disabling it results in backups being stored only within the single region chosen during provisioning. This makes your data vulnerable in a BCDR scenario, since you then have no means for recovery yourself. Therefore, it is not recommended to disable it, unless your data privacy restrictions require it. The recovery process when you have backups available in another region is to have available or provision a second Azure Synapse Analytics workspace in the paired region and recover in that secondary region. The recovery is performed by provisioning a new dedicated SQL pool in the new workspace and using the most recent backup to populate it. Refer to Figure 3.28 and look at the Use Existing Data option on the Additional settings tab. There is an option to select a backup. When selected, and after a successful provision, the data will be available on that dedicated SQL pool in that new region.
There is a tight dependency between Azure Synapse Analytics and ADLS, especially when you are working with files. Recall Exercise 3.1, where you provisioned an Azure storage account and created an ADLS container. The chosen replication option was LRS, which means the platform is not making copies to another region or zone. As shown in Figure 4.12, it is possible to change this from LRS to either GRS or RA‐GRS.
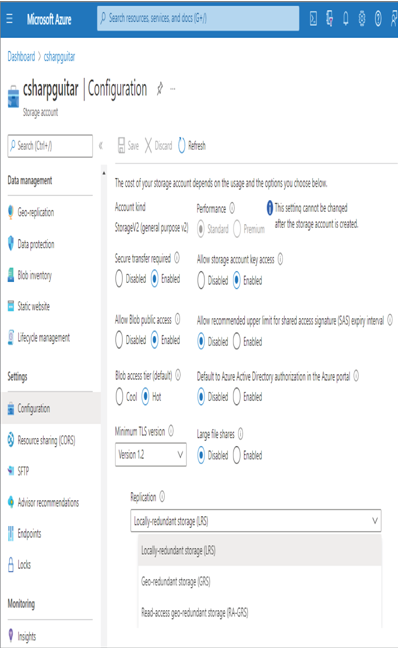
FIGURE 4.12 Data redundancy ADLS replication options
You cannot make this change when the region is having any kind of outage. This replication needs some time to complete its tasks and must be configured prior to its need, which is the definition of being redundant. LRS is recommended for testing purposes only; for production use, choose the one that conforms to your data residency requirements. But it is important to have at least one additional copy.
When you begin to provision your resources for running your data analytics on Azure, keep data redundancy in mind. Consider two Azure Synapse Analytics. The first model isolates data to different Azure storage accounts and ADLS containers per data landing zone (DLZ) stage (see Table 3.4). Figure 4.13 illustrates what this might look like. The Azure Synapse Analytics workspace on the far right illustrates the fact that multiple workspaces can point to the same ADLS container.
Each Azure storage account and its corresponding ADLS container can be in different regions too. These ADLS containers that contains your data could act as backups for each other by using tools like AzCopy or Azure Data Explorer to preemptively copy or move data manually. When one of the regions is having some problems, provision a new workspace in the region where the backup exists and point the workspace to the backed up data in that ADLS container.
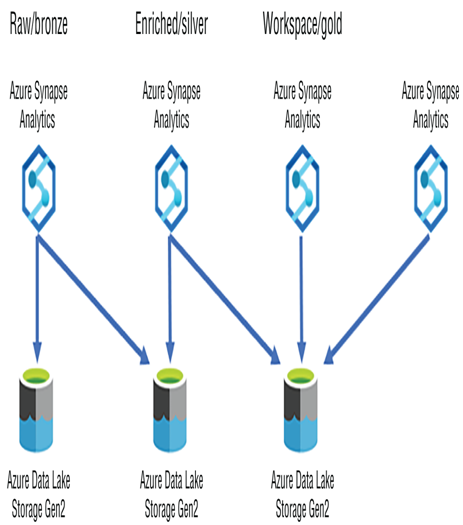
FIGURE 4.13 Data redundancy backups Azure Synapse Analytics regional redundancy per DLZ stage model
In the second model you store all DLZ stages in a single Azure storage account with an ADLS container per DLZ stage and point all workspaces to the appropriate one, as shown in Figure 4.14.
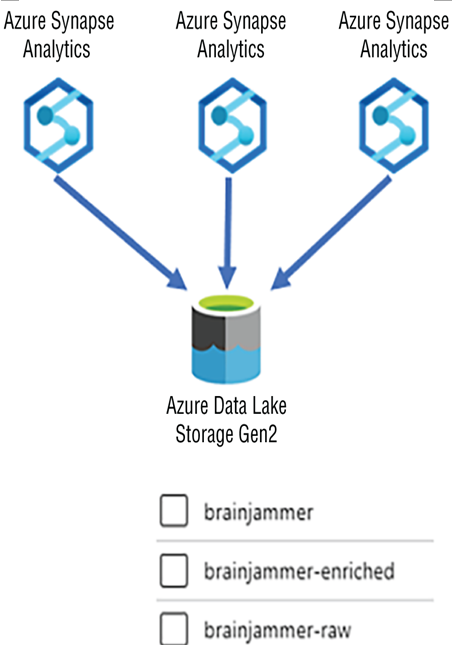
FIGURE 4.14 Data redundancy Azure Synapse Analytics single redundancy model containing all DLZs
This model, if configured with something other than LRS replication, will result in the data being copied into another region or zone. In this BCDR scenario, recognize that the RPO goal is 24 hours, which might be longer than desired. It is important to mention that the GRS, ZRS, and GZRS data copies are available for BCDR scenarios only; you cannot make them readable and writable them yourself. Those managing the platform, i.e., Microsoft, will be well aware of the outage. They will take appropriate actions to provide you with the new available data source within the RPO goal of 24 hours. Note that RPO defines the maximum time it could take to get the snapshot back; it does not consider the amount of time required to make the data available. RA‐GRS and RA‐GZRS provide read‐only capabilities, which might be useful for some scenarios, but ingestion (writes) will not work. Therefore, in most scenarios, if your data is highly critical and must be available to all at all times, then the data in an ADLS container needs to be regularly transferred between regions using a custom solution. Finally, as a Spark pool works primarily with the files stored in the ADLS container, having a plan for the content on ADLS is the solution for these kinds of pools as well.
Related Post

Build a Logical Folder Structure – The Storage of Data
No single folder structure fits every solution; what is considered a logically designed folder structure [...]
Implement Logical Data Structures – The Storage of Data
Unlike physical data storage structures, you cannot actually touch logical storage structures. That is because [...]