Azure Synapse Analytics Data Hub SQL Script – The Storage of Data

- Either log in to the Azure portal at https://portal.azure.com and navigate to the Azure Data Lake storage container you created in Exercise 3.1 or use Microsoft Azure Storage Explorer and navigate to the same ADLS container ➢ and then create the following directory structure:
EMEA/brainjammer/in/2022/04/01/18 - Download the file brainjammer_brainwaves_20220401.zip from Chapter04/Ch04Ex05 directory on GitHub ➢ extract the files from the compressed file ➢ and then upload them to the directory you just created. Your folder should resemble Figure 4.19.
FIGURE 4.19 Azure Synapse Analytics Data hub ADLS directory
- Navigate to the Azure Synapse Analytics workspace you created in Exercise 3.3 ➢ on the Overview blade, click the Open link in the Open Synapse Studio tile ➢ select the Develop hub ➢ click the + to the right of the Develop text ➢ and then click SQL Script and enter the following script:
SELECT TOP 100 *
FROM
OPENROWSET(
BULK ('https://*.dfs.core.windows.net/./EMEA/brainjammer/in/2022/04/01/18/*.csv'),
FORMAT = 'CSV',PARSER_VERSION = '2.0',HEADER_ROW = TRUE) AS [result]
- Make sure to update the HTTPS address to point to your ADLS container, and then run the query. The output resembles Figure 4.20. Consider renaming the SQL script ➢ hover over the value in the Develop SQL Scripts group ➢ click the ellipse (…) ➢ select Rename ➢ provide a useful name (for example, Ch04Ex05) ➢ and then click the Commit button, which will place the file on the GitHub you configured in Exercise 3.6.
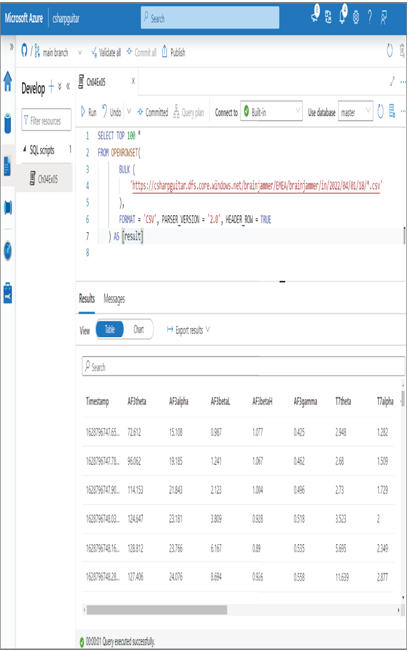
FIGURE 4.20 Azure Synapse Analytics Data hub ADLS directory
Notice in Figure 4.20 that the SQL pool running this query is the serverless one, i.e., built‐in. Remember that in the context of a serverless SQL pool, you can create only external tables. At the time of this writing, external table support is in preview regarding dedicated SQL pools, which can only be used with Parquet files. The benefit external tables have over managed tables is that the data remains in your data lake. An external table is a logical representation of that data, so when or if the external table is dropped, the data remains in the data lake. However, if you drop a managed table, then the data within it is also removed and lost.
KQL Script
When working with Data Explorer pools, this is the feature to choose. KQL scripts enable you to execute Kusto‐like queries on your Azure Data Explorer clusters. At the time of this writing, Data Explorer pools are in preview. They were covered in the previous chapter and introduced in Chapter 1.
Notebook
Choose the Notebook menu item to execute PySpark (Python), Spark (Scala), .NET Spark (C#) or Spark SQL code. Complete Exercise 4.6 prior to Exercise 4.7, as the files used to convert to Parquet in Exercise 4.7 are the ones you uploaded in Exercise 4.6.
Related Post

Schema Modifier – The Storage of Data
Consider adding a few additional transformations and viewing the configuration details. Add an Aggregate schema [...]
Business Continuity and Disaster Recovery – The Storage of Data
In the scenario just discussed, where data has been corrupted or deleted, the system hosting [...]