Azure Synapse Analytics Develop Hub Notebook – The Storage of Data

- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the Azure Synapse Analytics workspace you created in Exercise 3.3 ➢ on the Overview blade, click the Open link in the Open Synapse Studio tile ➢ select the Develop hub ➢ click the + to the right of the Develop text ➢ and then click Notebook.
- Select the Apache Spark pool you created in Exercise 3.4 from the Attach to drop‐down text box ➢ and then enter the following syntax into the code cell, replacing @ in the endpoint with your containderName@accountName:
%%pyspark
df = spark.read.option(“header”,”true”) \
.csv(‘abfss://@.dfs.core.windows.net/EMEA/brainjammer/in/2022/04/01/18/*’)
display(df.limit(10))
- Run the code. The first time you run the code in a cell, it can take up to 3 minutes for the Spark pool to instantiate. Be patient. The result should resemble Figure 4.21.
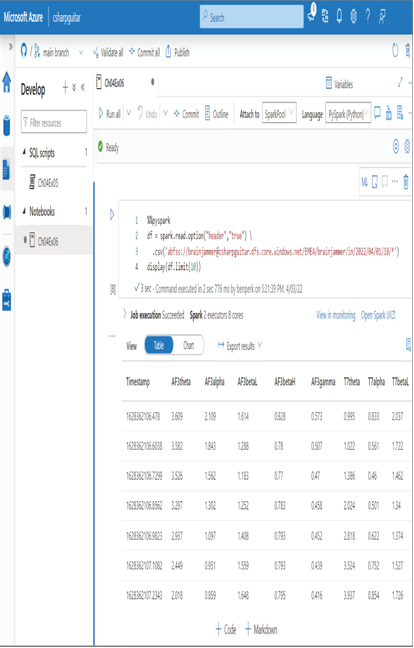
FIGURE 4.21 Azure Synapse Analytics Develop hub load Notebook
- Use either Microsoft Azure Storage Explorer or the Azure Portal at https://portal.azure.com and navigate to the Azure Data Lake storage container you created in Exercise 3.1 ➢ navigate to the same ADLS container as you did in Exercise 4.6 ➢ and then create the following directory structure:
EMEA/brainjammer/out/2022/04/03/17 - Access the file saveBrainwavesAsParquet.txt from GitHub at https://github.com/benperk/ADE, in the Chapter04/Ch04Ex6 directory ➢ place the syntax into the cell ➢ and then run the code. Parquet files, similar to those shown in Figure 4.22, are created and stored.
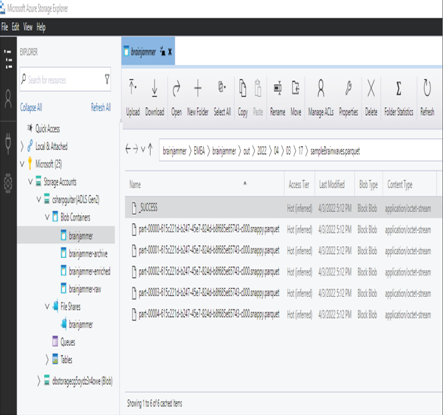
FIGURE 4.22 Azure Synapse Analytics Develop hub write Notebook Parquet files
- Click the Commit button to save the code to the GitHub you configured in Exercise 3.6.
In this exercise you loaded CSV files into a DataFrame, manipulated it (aka transformed it) by removing an invalid character from the headers, and saved the result as Parquet to ADLS. You did not perform any data analytics on this; it was simply a conversion. However, this is the place where you would perform some preliminary analysis on the files, to determine what exists and how it needs to progress further through the Big Data pipeline. You can load data from the files into temporary tables and run SQL‐like queries against them, or you can load data into memory and manipulate it there. The capabilities here are great and provide a platform capable of supporting anything within your imagination.
Data Flow
You can think of a data flow as an activity that will become part of a pipeline. The capabilities available on the Data flow blade are similar to the Power Query capability found in Azure Data Factory (ADF), in that it is a place to load some data from your data lake, perform some work on it, and once you like the output, you can save it and include is as part of your overall Big Data solution. There are a lot of capabilities in the Data Flow context. Complete Exercise 4.8 to get some hands‐on experience.
Related Post

Additional Data Storage Topics – The Storage of Data
This section will help you increase your knowledge of two of Azure open‐source products and [...]
Build a Temporal Data Solution – The Storage of Data
AUTHORIZATION dbo FIGURE 4.31 Finding the history table WHERE SCENARIO_ID = 2 SELECT * FROM [...]