Build External Tables on a Serverless SQL Pool – The Storage of Data

- Log in to the Azure portal at https://portal.azure.com ➢ navigate to the Azure Synapse Analytics workspace you created in Exercise 3.3 ➢ on the Overview blade, click the Open link in the Open Synapse Studio tile ➢ select the Develop hub ➢ click the + to the right of Develop ➢ select SQL Script from the pop‐up menu ➢ ensure that Built‐in is selected from the Connect To drop‐down list box ➢ and then execute the following SQL syntax:
CREATE DATABASE BRAINJAMMER
COLLATE Latin1_General_100_BIN2_UTF8
- Ensure that the database you just created (BRAINJAMMER) is selected from the Use Database drop‐down list box ➢ enter the following SQL syntax, which creates an external data source ➢ reference the Parquet file you created in Exercise 4.7 ➢ and then change * in the URI to your endpoint details.
CREATE EXTERNAL DATA SOURCE SampleBrainwavesSource
WITH (LOCATION = ‘abfss://@.dfs.core.windows.net’)
- Execute the following SQL syntax, which creates the external file format:
CREATE EXTERNAL FILE FORMAT SampleBrainwavesParquet
WITH (FORMAT_TYPE = PARQUET)
- Execute the SQL syntax required to create the external table. The file createExternalTables.sql, in the folder Chapter04/Ch04Ex10, on GitHub at https://github.com/benperk/ADE, contains the SQL to perform all these activities.
CREATE EXTERNAL TABLE SampleBrainwaves
([Timestamp] NVARCHAR(50),[AF3theta] NVARCHAR(50),[AF3alpha] NVARCHAR(50),[AF3betaL] NVARCHAR(50),…)
WITH(LOCATION = ‘EMEA/brainjammer/out/2022/04/03//.parquet/*’,DATA_SOURCE = SampleBrainwavesSource,FILE_FORMAT = SampleBrainwavesParquet)
- Select the data stored in Parquet format on ADLS using the following SQL command:
SELECT TOP 10 * FROM SampleBrainwaves - After retrieving some data, navigate to the Data hub ➢ expand SQL Database ➢ expand the database you created in step 1 ➢ and then look into all the additional folders. You should see something similar to Figure 4.33.
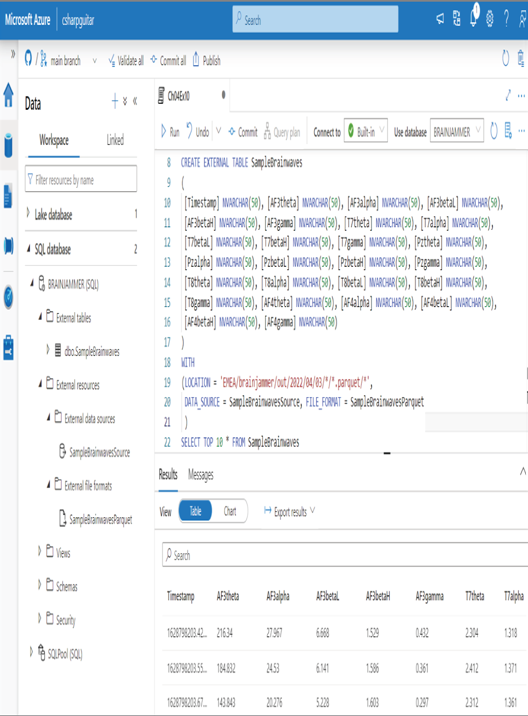
FIGURE 4.33 Building an external table
- Consider renaming the SQL script, and then commit it to your GitHub repository.
You might have noticed when you created the database that there was another line of SQL using the COLLATE command. This command is very important, as it instructs the DBMS how to compare and sort character data. Note that Latin1_General_100_BIN2_UTF8 is the collation that renders optimal performance for reading Parquet files and from Azure Cosmos DB. After creating the database on the serverless built‐in SQL pool, you need three components to build an external table. The first component is the external data source that provides, in this example, a pointer to the ADLS endpoint. Table 4.7 describes the supported location settings.
TABLE 4.7 External location endpoints and protocols
| External data source | Prefix | Path |
| Azure Blob Storage | wasb[s] | [email protected] |
| Azure Blob Storage | http[s] | account.blob.windows.net/containerfolders |
| ADLS Gen2 | http[s] | account.dfs.core.windows.net/container/folder |
| ADLS Gen2 | abfs[s] | [email protected] |
Notice in Exercise 4.11 that you did not provide a DATA SOURCE TYPE, which means you are using the native capabilities versus Hadoop (which is supported, so you could have used it, had you deployed to a dedicated SQL pool). Native table types are the default and the only supported table type for serverless SQL pools; therefore, declaring a table TYPE is not required.
The next required component is an external file format object. This identifies which type of file will be loaded into the external table; the options are either PARQUET or DELIMITEDTEXT.
Finally, you create the table with a schema that matches the contents of the files being loaded into it. Notice that instead of using CREATE TABLE, you must use CREATE EXTERNAL TABLE, and at the end there is a WITH clause, which includes a pointer to the two previously created components, the DATA_SOURCE and the FILE_FORMAT. One additional attribute, LOCATION, identifies the directory path to search for the files to load; in this case, the following snippet was configured. The wildcard search loads all Parquet files uploaded to the path on March 3, 2022.
LOCATION = ‘EMEA/brainjammer/out/2022/04/03//.parquet/*’
When you are working with a Spark pool, the closest object to an external table is realized using the saveAsTable(tableName) method. After creating the table and populating it with data, you can perform SQL commands against the table using Spark SQL, like the following code snippet:
Spark.sql(‘select * from tableName’).show()
Implement File and Folder Structures for Efficient Querying and Data Pruning
The actions you can take to make your file and folder structures most efficient for querying and pruning are based primarily on two notions. First, organize the data files in a way that intuitively specifies enough information to know what is contained within them. You should be able to get a good idea about its content simply by looking at the folder structure and/or filename. The other idea is to partition the file into a structure that is optimal for the kinds of queries that will be run against the data file. For example, if you or your users query based on a given timeframe, it makes sense to partition the data based on the year, month, and day when the data was created and ingested. To implement such a file and folder structure, complete Exercise 4.12, where you will convert a CSV file to Parquet, partition it, move it to a more intuitive directory, and query it.
Related Post

Implement Logical Data Structures – The Storage of Data
Unlike physical data storage structures, you cannot actually touch logical storage structures. That is because [...]
Azure Synapse Analytics Data Hub Data Flow – The Storage of Data
DROP TABLE brainwaves.DimELECTRODE 2. Create an SCD table, and then execute the following SQL script, [...]