Flowlets – The Storage of Data

A flowlet is a container that holds reusable activities. Consider the activity you created in Exercise 4.8, which retrieves brain wave data and converts the epoch date into a more human‐readable format. You can now place those transformations into a flowlet. Then, if you ever need that same set of transformations, you can use the flowlet instead of duplicating the configuration and the code within the Derived Column. In many cases the code and transformations that take place will be much more complicated. Being able to group sets of transformation activities into a container and then reuse that container has benefits. If something in the pipeline changes and requires a modification, then you would need to modify it in only a single place, instead of everywhere. To create a new data flow flowlet containing the transformations, right‐click the transformation in the location where you want the flowlet to stop, and then select Create a New Flowlet. This flowlet can now be used in other data flows.
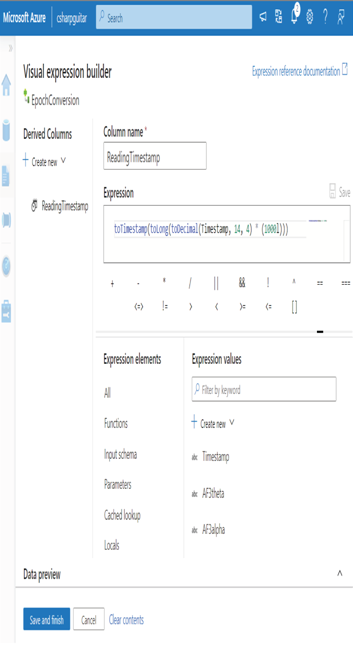
FIGURE 4.28 Azure Synapse Analytics Develop hub, Visual Expression Builder
Destination
The sink is the location you intend to store the data once the transformation has been performed. Where and how you store the transformed data has much to do with the kind of data and the DLZ stage of the transformation. Should the data be stored back in an ADLS container or in an Azure SQL relational database? Perhaps the output is a JSON document that needs to be immediately available globally, making Azure Cosmos DB a valid option. Table 4.5 provides some additional information about data flow transformation features.
TABLE 4.5 Data flow transformation features
| Category | Name | Description |
| Formatters | Flatten | Converts hierarchical files like JSON and unrolls them into individual rows |
| Parse | Parses data from the incoming stream | |
| Stringify | Converts complex data types to a string | |
| Multiple inputs/outputs | Conditional split | Routes data rows to different streams based on a matching data pattern or condition |
| Exists | Checks whether data exists in a second stream or data flow | |
| Join | Combines data from multiple sources | |
| Lookup | References data that exists in a different second stream or data flow | |
| New branch | Performs multiple operations on the same data stream | |
| Union | Combines data from multiple sources vertically | |
| Row modifier | Alter row | Sets delete, insert, update, and upsert row policy |
| Assert | Sets an assert rule per row that specifies allowed values | |
| Filter | Filters data based on a configured condition | |
| Sort | Sorts incoming data rows |
In summary, a data flow consists of a source, a sink, and one or more transformations, as described in Table 4.4 and Table 4.5. You can construct a flowlet from a subset of transformations within a data flow for reuse in other data flows. As you will soon learn, one or more data flows are considered activities that are added to a pipeline. The pipeline is responsible for initiating, executing, monitoring, and completing all the activities within it.
Related Post

Build a Logical Folder Structure – The Storage of Data
No single folder structure fits every solution; what is considered a logically designed folder structure [...]
Implement Data Archiving – The Storage of Data
FIGURE 4.17 Implement data archiving access tier The moveToCold lifecycle management policy moves any file [...]